Recently while working on uml-cpp, which is an object pool of UML types used for the uml.cafe backend, I realized that there could be serious use in making the strategies I used available in a generic sense. So the last couple weeks in my free time I have taken the core functionalities of uml-cpp and packaged them into a header only library for easy reuse and object pool implementations. Hence egm was born, I want to walk through the library and some of the fun C++ strategies I used to make it easier and faster to run the library for users.
The Manager
So EGM stands for EGM Generic Manager, inspired by other recursive software acronyms like GNU and YAML. A manager in this sense just means a C++ object to control the memory of other objects. The manager is generic because it can be used for multiple types through its template parameters. The signature for the manager object in EGM, EGM::Manager looks like the following:
template <class TypeList, class StoragePolicy>
class Manager;
We can ignore the StoragePolicy template parameter for now, but the TypeList template parameter is fundamental to the implementation of other Managers using EGM::Manager. A C++ TypeList is a type that serves as a list of other Types. On a quick side note I do highly recommend reading Alex Andrescu’s “C++ Generic Programming and Design Patterns Applied”, because a lot of the concepts I use are contained within that book. The TypeList provided to the manager is just the list of Types that we want to manage objects of. So if we had two types Foo and Bar, we would provide a TypeList holding both of them to a manager to manage their types, which would look something like this pseudo code:
using FooBarManager = Manager<TypeList<Foo, Bar>>;
Now that is pseudo code because the types provided to the manager need to be constructed in a certain patterns themselves. All types to the manager need to be first, a policy class. A policy class is simple a class that inherits template parameter:
template <class Policy>
class PolicyClass : public Policy { };
The reason it needs to be a policy class is because the Manager injects generated functionality into your types through that policy class relationship, we will dive into that when we go into GenBaseHierarchy later. Now EGM provides a special TypeList to allow the manager to handle these types, this TypeList is called EGM::TemplateTypeList in the code, you can see its definition here. It provides helper types like TemplateTypeListSize, TemplateTypeListIndex,TemplateTypeListCat, TemplateTypeListAppend etc. to mutate and get info from the type list. So a valid but incomplete definition of a Manager would be something like this:
using FooBarManager = Manager<TemplateTypeList<Foo, Bar>>;
Now before diving fully into the types lets look at what the manager can do, what would an Object Pool Manager do? Well the main functions of the Manager are listed briefly below:
// Instantiating a Manager
FooBarManager m;
// Creating an object
auto foo = m.create<Foo>();
// manager provides ids to track objects
EGM::ID foo_id = foo.id();
// release object from memory
m.release(foo);
// acquire object into memory
foo = m.acquire(foo_id);
// or
foo = m.get(foo_id);
// erase object completely
m.erase(foo);
So as you can see the general functionality entails, creating objects, keeping track of objects, controlling the memory of those objects, and deleting those objects. No lets see how to create proper types to be used by the manager!
The Types
Now as I was stating before our special types have to be defined in a special manner. Beside’s being a template class there are some key concepts that need to be applied to the type. First of all, all references to other Types controlled by the manager, they need to be stored in some version of an EGM::AbstractSet. EGM functions by using basic set theory to minimize size and also put associations with other types to reduce duplicate code. The Manager handles references internally through these set objects. I won’t dive into the implementation of the Set or the Reference mechanics of the Manager because they are a little too complicated to discuss with everything else in this article, but I will discuss how to use these sets. A basic Set to just hold references of other types would be defined similar to so:
template <class> class Bar; // forward decaration
template <class ManagerPolicy>
class Foo : public ManagerPolicy {
EGM::Set<Bar, Foo> bars = EGM::Set<Bar, Foo>(this);
};
template <class ManagerPolicy>
class Bar : public ManagerPolicy {};
// usage
FooBarManager m;
auto foo = m.create<Foo>();
auto bar = m.create<Bar>();
foo->bars.add(bar);
cout << "foobars front: " << foo->bars.front().id()
Now there are plenty of different Set Types, here is a list of all of them:
- ReadOnlySet – a set that can only be read from
- Set – a set that is mutable
- Singleton – a set that can only hold one element
- ReadOnlySingleton – an immuatable Singleton
- OrderedSet – a set that preserves order
- ReadOnlyOrderedSet – an immuatable ordered set
Now sets can subset and redefine other sets (this is all very familiar to UML properties) through their subsets and redefines functions. They can also be marked as opposites to other sets in other types. All of this functionality should be put in a private function called init, these are called when you put the EGM MANAGED_ELEMENT_CONSTRUCTOR macro in your type. Here is definition of Foo and Bar that provides a relationship between foo.bars and a new set bar.foos as opposite to eachother:
template <class ManagerPolicy>
class Foo : public ManagerPolicy {
using BarsSet = EGM::Set<Bar, Foo>;
BarsSet bars = BarsSet(this);
private:
void init() {
bars.opposite(&BarsSet::ManagedType::getFoos);
}
public:
MANAGED_ELEMENT_CONSTRUCTOR(Foo);
BarsSet& getBars() { return bars; }
};
template <class ManagerPolicy>
class Bar : public ManagerPolicy {
using FoosSet = EGM::Set<Foo, Bar>;
FoosSet foos = FoosSet(this);
private:
void init() {
foos.opposite(&FoosSet::ManagedType::getBars);
}
public:
MANAGED_ELEMENT_CONSTRUCTOR(Bar);
FooSet& getFoos() { return foos; }
};
FooBarManager m;
auto foo = m.create<Foo>();
auto bar = m.create<Bar>();
foo->bars.add(bar);
// following will print out barfoos size: 1
cout << "barfoos size: " bar->foos.size();
Now these types can have more than just relations to each other they can hold data as well. But before we go into customizing our types more, we need to provide some more information about our types to the manager. All types that are provided to a manager need to have a specialization for EGM::ElementInfo. This structure just provides compile time information to the Manager about our type that the Manager needs, if the Manager is set up to Serialize data which it is by default, then we need to atleast provide a method in ElementInfo called name that returns a string. If our type has any sets or data we need to provide sets and data functions that returns mappings to string data to identify the sets and data. If you want your type to be abstract, there needs to a static bool value named abstract set to true.
Besides just the template specialization, each type needs to have an alias called Info referencing it’s inheritance pattern and binding it to the ElementInfo specialization. Building on our Foo Bar example lets create a new type named FooDerived that inherits from Foo and has a data field called field:
template <class ManagerPolicy>
class FooDerived : public ManagerPolicy {
public:
// provide TypeInfo binding to identify that
// FooDerived inherits from Foo
using Info = TypeInfo<FooDerived, TemplateTypeList<Foo>>;
// define a data field
string field = "";
private:
void init() {} // nothing to do
public:
MANAGED_ELEMENT_CONSTRUCTOR(FooDerived);
};
namespace EGM {
template <>
struct ElementInfo {
static string name() { return "FooDerived"; }
template <class Policy>
class FieldPolicy {
ManagedPtr<FooDerived<Policy>> el;
FieldPolicy(FooDerived<Policy>>& el) : el(el) {}
std::string getData() {
return el->field;
}
void setData(std::string data) {
el->field = data;
}
};
template <class Policy>
static DataList data(FooDerived<Policy>& el) {
return DataList {
createDataPair<FieldPolicy<Policy>>("field", el)
};
}
};
}
using DerivedFooManager = EGM::Manager<
TemplateTypeList<Foo, Bar, FooDerived>
>;
DerivedFooManager m;
auto foo = m.create<FooDerived>();
auto bar = m.create<Bar>();
foo->bars.add(bar);
foo->field = "hello world";
// etc...
Now this is most of the configuration involved in creating EGM compatible data types. Feel free to look at more complex examples in the tests defined for egm. But I am going to stop here for configuring the Types, now that we can see the necessary definitions involved.
The Implementation
Now after configuring your Manager it seems almost like magic that it can create all of these types you have defined, and construct them and manage them. First thing after going through all of that, is how does the manager construct and create the objects it does through the types we provide. I was using auto for all of the returns from create so you don’t really understand the types that the manager is generating. Well to uncover the curtain, create<>() which is defined here, looks like this:
template <template <class> class Type>
ManagedPtr<Type<GenBaseHierarchy<Type>>> create() {...
Now this create takes a template template parameter, which makes sense with how we define our types and pass them to create. Now the Type returned is a bunch of template classes, let’s go through them one by one:
ManagedPtr
So ManagedPtr is a special implementation of a smart pointer. It functions similar to std::shared_ptr, in fact it is just a wrapper around it. The additional functionality is that ManagedPtr can be used to count how many references are currently using it to automatically free memory. ManagedPtr ties into the object pool mechanics of the manager by allowing you to acquire, release and get the id of the ptr through it’s acquire, release and id methods.
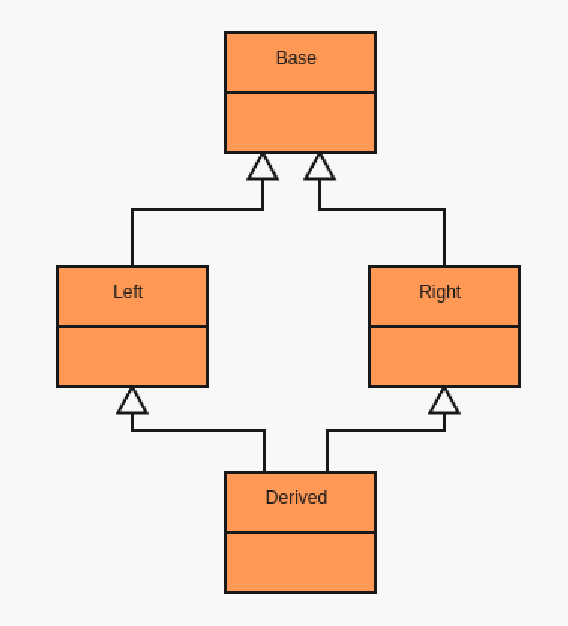
GenBaseHierarchy
Now this type is a little bit more complex. This type takes the information you provided in your types and constructs a valid inheritance pattern to be used within the manager. So you see that the ManagedPtr returned by create holds a Type<GenBaseHierarchy<Type>>, so you can see that GenBaseHierarchy<Type> is the policy that the manager fills out our policy class with. GenBaseHierarchy's signature is defined below:
template <
template <class> class T, // our policy class
class Bases = typename T<BaseElement>::Info::BaseList
>
struct GenBaseHierarchy;
Now before looking at the implementation, we can see that there is a second Template Parameter with a default to the base list we defined in TypeInfo. So to build on this, the general purpose of GenBaseHierarchy is to manage inheritance. Now to implement this inheritance pattern, we virtually inherit every type from that base list, and then when there is no more base types to inherit, we inherit from the Manager’s BaseElement which holds ID and reference tracking. Here is the full Implementation of GenBaseHierarchy:
// No bases just inherit from BaseElement
template <template <class> class T>
struct GenBaseHierarchy<T, TemplateTypeList<>> : virtual public BaseElement
{
// Constructor implementation ...
};
template <
template <class> class T,
// spread out the typelist
template <class> class First,
template <class> class ... Types
>
struct GenBaseHierarchy<
T,
TemplateTypeList<First, Types...>
> :
// inherit first element GenBaseHierarchy virtually
virtual public First<GenBaseHierarchy<First>>,
// inherit rest of typelist recursively
public GenBaseHierarchy<T, TemplateTypeList<Types...>>
{
// Constructor implementation ...
};
Now it’s a little packed, but the idea is that the template specializations break out GenBaseHierarchy into different parts to inherit from all bases. So when the Manager is creating your objects of your type, it makes sure that all bases are in the proper place, and other managers can configure them differently. In the end this allows you to reuse your types with different managers to achieve different effects, simplifying implementations and allowing more reproducability.
To be continued…
So this article is getting a little long, I think I am going to split the second part, which is the Storage and Serialization policies that can be provided to the manager. With that we can take a look into more C++ design patterns used, including the Visitor pattern to compile time search hierarchies BFS or DFS, as well as possibly more! See you soon, and as always if you have any questions I check my email [email protected] so feel free to reach out to me there.